

小米 MiMo-V2.5 系列 API 在 2026 年 5 月 27 日 0 点完成一次永久调价。核心变化不是单一模型促销,而是价格表、Token Plan 和缓存计费规则同时重写:V2.5 Pro 国内缓存命中输入价降到每百万 Token 0.025 元,V2.5 降到 0.02 元;官方称最高降幅达到 99%。
价格表被重新压到 DeepSeek 级别
小米 MiMo 开放平台公告显示,本次调价在北京时间 2026 年 5 月 27 日 0 点生效,全球同步。官方给出的总括口径是:MiMo-V2.5 系列 API 永久降价,最高降幅 99%,且不再按输入长度区分价格。
新的国内按量价格如下:
| 模型 | 输入缓存命中 | 输入缓存未命中 | 输出 |
|---|---|---|---|
mimo-v2.5-pro |
0.025 元 / 百万 Token | 3 元 / 百万 Token | 6 元 / 百万 Token |
mimo-v2.5 |
0.02 元 / 百万 Token | 1 元 / 百万 Token | 2 元 / 百万 Token |
海外价格同步更新:
| 模型 | 输入缓存命中 | 输入缓存未命中 | 输出 |
|---|---|---|---|
mimo-v2.5-pro |
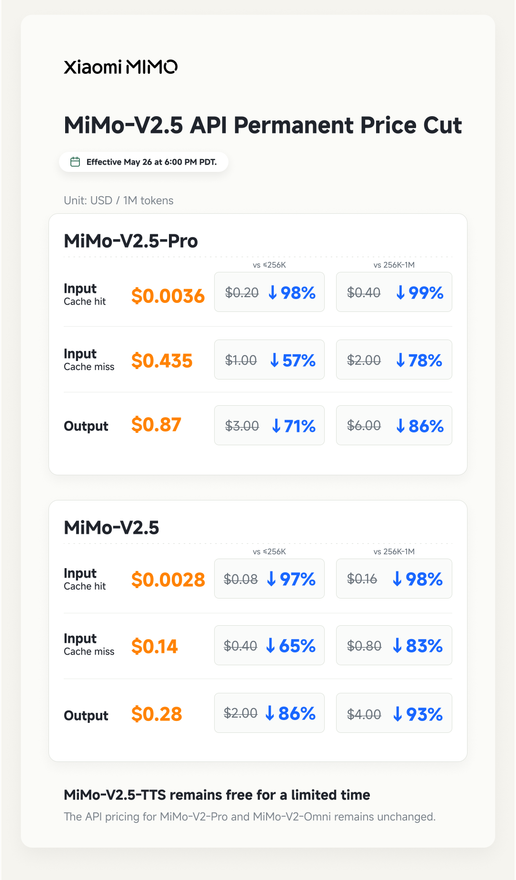
0.0036 美元 / 百万 Token | 0.435 美元 / 百万 Token | 0.87 美元 / 百万 Token |
mimo-v2.5 |
0.0028 美元 / 百万 Token | 0.14 美元 / 百万 Token | 0.28 美元 / 百万 Token |
这个价格结构把真正的成本重心放在缓存命中率上。对长上下文 Agent、代码助手和多轮工具调用来说,缓存命中输入的价格比输出价格更敏感。小米这次把 V2.5 Pro 缓存命中输入从旧 V2 Pro 的 1.40 元 / 百万 Token 压到 0.025 元 / 百万 Token,降幅接近 98.2%;如果按旧 V2 Pro 256K-1M 区间的 2.80 元计算,降幅约 99.1%。
Token Plan 从买额度变成买 Credits
这次不是只改按量 API。小米还把 Token Plan 的额度和换算规则一起重置。
官方价格图显示,Token Plan 在价格不变的情况下提高 Credits:
| 套餐 | 价格 | 调整前 | 调整后 |
|---|---|---|---|
| Lite | 6 美元 | 6000 万 Credits | 4.1B Credits |
| Standard | 16 美元 | 2 亿 Credits | 11B Credits |
| Pro | 50 美元 | 7 亿 Credits | 38B Credits |
| Max | 100 美元 | 16 亿 Credits | 82B Credits |
新的 Credits 换算规则更贴近实际调用成本:mimo-v2.5-pro 缓存命中、缓存未命中、输出分别消耗 2.5、300、600 Credits / Token;mimo-v2.5 分别消耗 2、100、200 Credits / Token。相比旧版 V2 Pro 的 140、700、2100 Credits / Token,缓存命中输入的权重被大幅压低。
小米还宣布,所有仍在有效期内的 Token Plan 用户额度在 5 月 27 日 0 点全量重置,且按新规则执行。这个动作会直接影响已经通过 MiMo Orbit 获得套餐权益的开发者,也覆盖 Apache Software Foundation 专属福利用户。
免费 Token 激励提前耗尽
MiMo Orbit 的 100T Token 创造者激励计划在 4 月 28 日启动,原计划持续到 5 月 28 日。小米在本次公告中披露,截至 2026 年 5 月 26 日 16:08,北京时间,100T Token 已全部发放完毕,活动提前结束。
这解释了调价时点:小米先用免费额度扩大开发者触达,再把价格体系改成可长期使用的按量和套餐模型。免费激励结束后,API 单价就是留存开发者的主要杠杆。
降价理由指向推理系统,而不是模型缩水
小米官方把降价归因于推理系统优化。公告提到,团队基于 SGLang HiCache 支持 SWA(Sliding Window Attention),将 KV Cache 在 GPU 显存、CPU 内存、SSD 等多级存储间的数据传输量降到优化前约 1/7,可缓存 Token 数提高到优化前约 5 倍。同时,团队还调整了专家并行方案和输入长度分桶策略。
这部分目前只有官方口径,尚未看到第三方对新价格下吞吐、延迟、缓存命中率和稳定性的独立复测。对开发者更实用的验证方式,是用自己的 Agent 工作流跑一轮长上下文任务,分别记录缓存命中比例、输出 Token、端到端延迟和实际账单。
开源模型价格战进入缓存计费阶段
MiMo-V2.5 系列在 4 月 28 日以 MIT 协议开源,官方称两个版本都支持 100 万 Token 上下文窗口。其中,MiMo-V2.5-Pro 面向 Agent 和 Coding,MiMo-V2.5 面向文本、图像、视频和音频理解。
这次降价把竞争点从“每百万 Token 名义价格”推进到三个更细的指标:
- 缓存命中输入能否真正便宜;
- 长上下文任务是否能保持稳定命中;
- 套餐 Credits 是否足够透明,能否让开发者预估月度成本。
如果只看价格表,MiMo-V2.5 Pro 已经进入国内主流推理模型的低价区间。但对 Agent 场景,账单通常不是由单轮 prompt 决定,而是由多轮工具调用、长上下文复用、缓存写入和输出长度共同决定。小米给出的新规则降低了缓存命中输入成本,真正的成本优势还要看实际工作流是否能吃到缓存。