OpenAI 发布 GPT Transcribe 与 GPT Live Transcribe 语音转录模型 2026-07-29 多模态 OpenAI 发布 GPT Transcribe 与 GPT Live Transcribe 语音转录模型,分别处理录音文件和实时音频。本文梳理两者的 API 接入方式、上下文提示能力、文件限制与每分钟价格,并说明文件流式输出与实时转录的区别,帮助开发者为会议记录、直播字幕和批量录音处理选择模型。
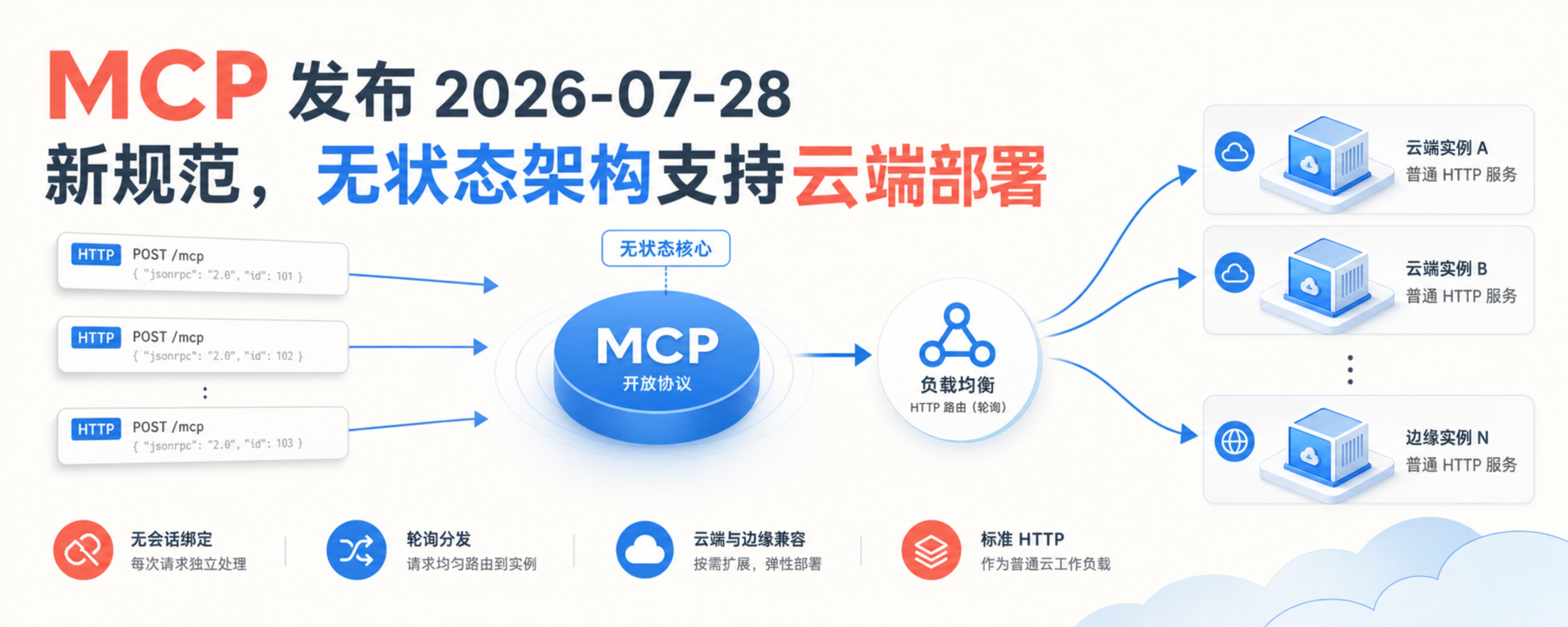
MCP 发布 2026-07-28 新规范,无状态架构支持云端部署 2026-07-29 智能体 MCP 发布 2026-07-28 新规范,协议核心改为无状态请求,远程 MCP 服务器不再依赖初始化握手、会话 ID、粘性路由或共享会话存储。本文说明它如何支持无服务器、边缘平台和普通负载均衡部署,以及开发者升级 SDK 时需要关注的协议变化。
OpenAI 恢复 Codex 5 小时限额,本周限额继续保留 2026-07-29 智能体 OpenAI 恢复 Codex 5 小时使用限额,本地消息与云端任务重新共享同一时间窗口,每周限额继续叠加。本文说明 Plus、Pro 等套餐的当前规则、查看入口,以及达到限额后购买积分、切换 GPT-5.4 mini 或使用 API 密钥继续工作的方式,帮助用户安排长任务并控制额外支出。
OpenAI 开源 Codex Security CLI,支持本地与 CI 扫描代码漏洞 2026-07-29 智能体 OpenAI 开源 Codex Security CLI 与 TypeScript SDK,采用 Apache-2.0 许可证,可在本地、提交前和 CI 流程中扫描代码并导出结构化结果。本文说明安装门槛、账号权限、扫描范围、结果保存注意事项,以及开源代码与云端扫描服务的边界,帮助开发者判断如何在个人项目、团队仓库和自动化流水线中安全使用。
火山引擎开放豆包搜索服务,支持 API、Skill 和 MCP 接入 2026-07-28 智能体 火山引擎开放豆包搜索服务,企业和开发者可通过 API、Skill、MCP 或 Agent Plan 为智能体接入联网检索。服务支持 Markdown 与结构化数据返回,每月提供 500 次免费搜索额度,本文说明开放对象、接入路径、计费边界,以及普通用户会在哪里间接用到这项能力。
月之暗面开放 Kimi K3 模型权重,同步发布技术报告 2026-07-28 大模型 月之暗面开放 Kimi K3 完整模型权重并发布技术报告。2.8 万亿参数模型采用 MoE 架构,支持约 100 万 Token 上下文和原生图像理解;本文说明 Hugging Face 下载体量、部署方式,以及 Kimi K3 License 对商业服务和大型产品的使用条件,帮助开发者判断自托管资源与合规边界。
多名在华 giffgaff 用户收到停服通知,长期境外使用被判定不符合资格 2026-07-27 行业观察 多名在中国使用 giffgaff 的用户于 7 月 27 日收到停服通知,邮件把长期或永久在英国境外使用列为不符合服务资格的原因。本文梳理通知内容、与半年无活动停号规则的区别,以及号码迁移、短信验证和余额处理步骤。
腾讯让 QQ 宠物回归手机端,升级 3D 形象并接入 Hy3 2026-07-27 行业观察 QQ宠物于7月27日回归安卓和iOS版手机QQ,采用3D企鹅、狗狗与蒜头鹅形象,保留喂食、洗澡、打工等养成玩法,并接入腾讯Hy3大模型提供主动回应、宠物日记与好友互动。本文说明入口、核心变化和普通用户的使用方式。
OpenAI 将于 8 月 9 日停用 Atlas 2026-07-27 智能体 OpenAI 将于 2026 年 8 月 9 日停用 ChatGPT Atlas,并把浏览器智能体能力迁入 ChatGPT 与 Codex。本文说明书签、标签页、浏览历史和 ChatGPT 对话的迁移规则,以及 Atlas 用户在停用前需要完成的保存步骤,帮助用户避免在切换后丢失重要页面和工作入口等关键信息。
千问办公开放桌面客户端,支持 Office 文件与自动化任务 2026-07-27 智能体 千问办公开放 macOS 与 Windows 桌面客户端,可通过任务对话生成和编辑 Word、Excel、PPTX 与 HTML 等办公产物,并执行文件处理、网页操作和技能扩展。本文说明下载要求、个人版价格、使用方式与权限风险,帮助个人和团队判断它适合哪些工作,以及首次使用前需要完成哪些安全准备。