

MiniMax M3 已在官方页面和第三方 API 平台上线。官方把它定位为首个同时覆盖编程智能体、百万上下文和原生多模态的开源权重前沿模型,但截至发稿,权重与技术报告仍是“约 10 天内发布”的承诺,不能等同于权重已经公开可下载。
发布重点不是单一榜单,而是三项能力打包
MiniMax 在官方发布页中给 M3 的主标题是“Frontier Coding, 1M Context, Native Multimodality”。这三项分别对应编程与智能体任务、最高 100 万 token 上下文,以及从训练阶段开始的原生多模态能力。
这也是本次发布的核心卖点:不是只做长上下文模型,也不是只做编程模型,而是试图把代码生成、工具调用、长程上下文和图像/视频输入放进同一个通用模型。
官方披露的编码和智能体评测包括:SWE-Bench Pro 59.0%、Terminal Bench 2.1 66.0%、SWE-fficiency 34.8%、KernelBench Hard 28.8%、MCP Atlas 74.2%。这些数字目前主要来自 MiniMax 官方口径和其披露的内部评测流程,尚未看到独立第三方复现。
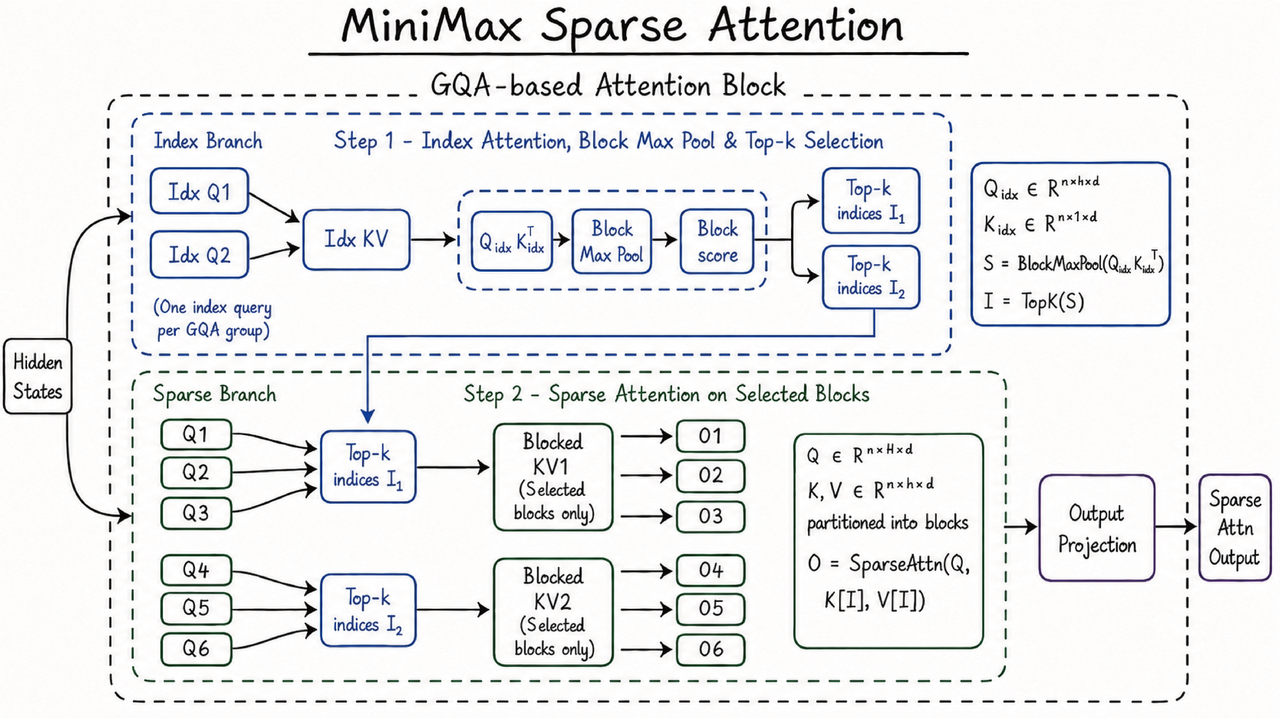
MSA 把百万上下文从容量问题变成成本问题
M3 采用 MiniMax Sparse Attention(MSA)。官方称,在 100 万 token 上下文规模下,M3 单 token 计算量约为上一代模型的二十分之一;预填充阶段加速 9.7 倍,解码阶段加速 15.6 倍。
这组数字的意义不在“上下文窗口更大”本身。百万上下文已经不是新概念,真正卡住工程落地的是读取长仓库、长视频和长任务历史时的成本与延迟。如果 MSA 的质量损失可控,长程 Agent 才有机会把完整代码库、历史 issue、终端日志和多轮工具调用历史留在同一个上下文里处理。
但这里仍要保留边界:MSA 的性能曲线、质量保持方式、训练细节和部署约束,需要等技术报告和权重发布后才能被社区验证。
API 已开放,权重还没真正落地
可用性上,M3 已出现在 MiniMax 官方导航、Vercel AI Gateway 和 OpenRouter 模型目录中。OpenRouter API 返回的模型 ID 是 minimax/minimax-m3,标注上下文长度为 1,048,576,输入形态为文本、图像、视频到文本输出;其顶层 provider 当前给出的可用上下文为 524,288。
价格方面,OpenRouter 目录显示 M3 限时 5 折后输入价格为 0.30 美元/百万 token,输出价格为 1.20 美元/百万 token,缓存读取为 0.06 美元/百万 token。第三方平台价格会随 provider 和促销变化,正式选型仍应以调用平台实时价格为准。
更关键的是“开源权重”状态。MiniMax 官方社交发布称权重和技术报告将在约 10 天内发布;Hugging Face 的 MiniMaxAI/MiniMax-M3 模型卡目前无法直接读取。也就是说,M3 现在可以通过 API 测试,但还不是一个已经完成社区复现链路的开源权重模型。